pyppeteer的问题
本身这个项目是非官方的,是基于谷歌官方puppeteer的python版本。
本来chrome就问题多多,puppeteer也是各种坑,加上pyppeteer是前两者的python版本,也就是产生了只要前两个有一个有bug,那么pyppeteer就会原封不动的继承下来,本来这没什么,但是现在遇到的问题就是pyppeteer这个项目从18年9月份之后就没更新过了,前两者都在不断的更新迭代,而pyppeteer一直不更新,导致很多bug根本没人修复。
遇到的错误:
-
pyppeteer.errors.NetworkError: Protocol error Network.getCookies: Target close
控制访问指定url之后await page.goto(url),会遇到上面的错误,如果这时候使用了sleep之类的延时也会出现这个错误或者类似的time out。
这个问题是puppeteer的bug,但是对方已经修复了,而pyppeteer迟迟没更新,就只能靠自己了,搜了很多人的文章,例如:https://github.com/miyakogi/pyppeteer/issues/171 ,但是我按照这个并没有成功。
也有人增加一个函数:async def scroll_page(page): cur_dist = 0 height = await page.evaluate("() => document.body.scrollHeight") while True: if cur_dist < height: await page.evaluate("window.scrollBy(0, 500);") await asyncio.sleep(0.1) cur_dist += 500 else: break但是我调用这个参数依然没解决问题。
后来有人说可以把python第三方库websockets版本7.0改为6.0就可以了,亲测可用。pip uninstall websockets #卸载websockets pip install websockets==6.0 #指定安装6.0版本20190825更新
上面websockets降级的方法在有些环境下会遇到错误create_connection() got an unexpected keyword argument 'ping_interval'
更简单的新方法,升级websockets到最新的8.0版本
pip install -U websockets
在launch里增加timeout参数,我设置的是360秒,因为国外网站有时候页面打开很慢,这样设置后就不会出问题了。
browser = await launch({'headless': False,'timeout':1000*360,}) -
chromium浏览器多开页面卡死问题
解决这个问题的方法就是浏览器初始化的时候launch里添加'dumpio':True。跟浏览器进程有关,至于什么原理我也不知道,只是添加上了。 -
浏览器窗口很大,内容显示很小
上面的问题是需要设置浏览器显示大小,默认就是无法正常显示。
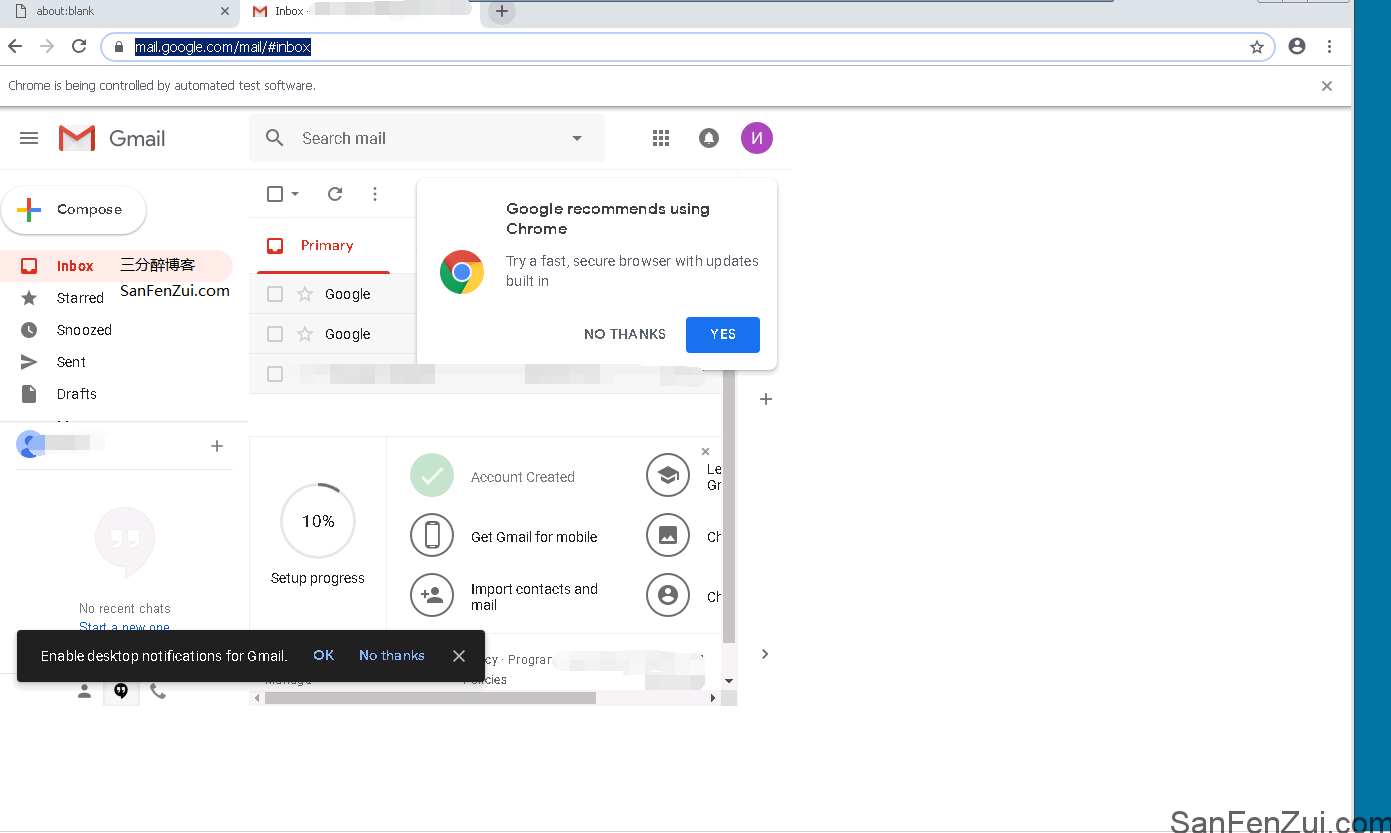
可以看到gmail页面只在左侧显示,右侧都是空白,网站内容并没有完整铺满chromium,底部横向滚动条拖拽还很不方便。browser = await launch({'headless': False,'dumpio':True, 'autoClose':False,'args': ['--no-sandbox', '--window-size=1366,850']}) await page.setViewport({'width':1366,'height':768})通过上面设置Windows-size和Viewport大小来实现网页完整显示。
但是对于那种向下无限加载的长网页这种情况如果浏览器是可见状态会显示不全,针对这种情况的解决方法就是复制当前网页新开一个标签页粘贴进去就正常了。 -
当使用时间pyppeteer一段时间之后,在
C:\Users\Administrator\AppData\Local\pyppeteer\pyppeteer\.dev_profile文件夹里会产生大量的文件,我的这个文件夹属性是16G,真的给我吓到了,其中Administrator有个人电脑不是这个用户名,是自己设定的,需要自己替换一下。
下面是帖子https://segmentfault.com/a/1190000018873537 解决办法
将pyppeteer类和websockets.protlcol类的log设置为WARNING级别,可以避免WARINIG级别下的log输出。此法,可以节省程序打印无用日志的时间和日志占用的巨大空间。import logging pyppeteer_level = logging.WARNING logging.getLogger('pyppeteer').setLevel(pyppeteer_level) logging.getLogger('websockets.protocol').setLevel(pyppeteer_level) pyppeteer_logger = logging.getLogger('pyppeteer') pyppeteer_logger.setLevel(logging.WARNING)在github上崔大佬开了issue,讨论避免pyppeteer类和websockets.protlcol类打印大量日志的问题。github地址
但是实际我测试,这个样设置依然会在这个文件夹里产生tmp文件,对于这个问题我还没找到可禁止产生的方法,目前就是手动定期删除下。 -
程序运行自动下载chromium提示ssl错误
[W:pyppeteer.chromium_downloader] start chromium download. Download may take a few minutes. HTTPSConnectionPool(host='storage.googleapis.com', port=443): Max retries exceeded with url: /chromium-browser-snapshots/Win_x64/575458/chrome-win32.zip (Caused by SSLError(SSLError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:833)'),))
解决办法:打开C:\Python36\Lib\site-packages\pyppeteer\chromium_downloader.py,替换里面DEFAULT_DOWNLOAD_HOST = 'https://storage.googleapis.com'为DEFAULT_DOWNLOAD_HOST = 'http://storage.googleapis.com'即可,具体路径替换成自己的python路径。 -
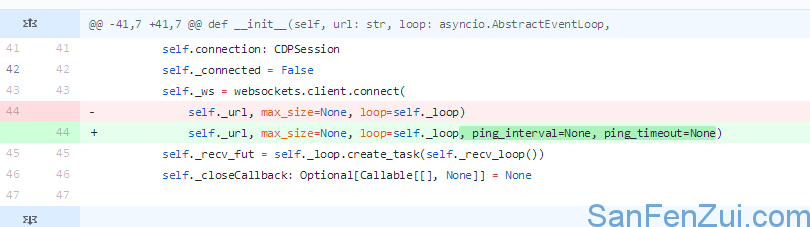
pyppeteer.errors.NetworkError: Protocol error Runtime.evaluate: Target close
打开新标签页遇到的,解决办法根据https://github.com/miyakogi/pyppeteer/pull/160/files 这个文件进行更改pyppeteer包里面的connection.py文件即可。
-
无法关闭chrome is being controlled by automated test software(Chrome 正受到自动测试软件的控制)这个控制条, 之前的设置是在args里添加
'--disable-infobars',但是并没有效果,后来查到https://github.com/GoogleChrome/puppeteer/issues/2070 发现原来从chrome v7.6以后已经去掉了这个设置,现在需要在浏览器的lanch添加'ignoreDefaultArgs': ['--enable-automation']就可以了。这样设置后的确是去掉了那个控制条, 但是在chrome V7.8版本会提示--no-sandbox失败, 导致无法正常使用。坑实在是太多了, 无力吐槽。 -
使用browser=await pyppeteer.launcher.connect({'browserWSEndpoint':wsEndpoint})可以重新连接已经打开的chrome浏览器进行操作,但如何此时的浏览器进行被关闭或者结束了, 这个连接过程会一直卡住, 并不会超时报错.通过下断点发现是laucher.py里面的
browserContextIds = (await connection.send('Target.getBrowserContexts') ).get('browserContextIds', [])这里的判断出了问题, 进一步追踪到是connection.py这个文件的85行,判断这里
if self._lastId and not self._connected: raise ConnectionError('Connection is closed')将and改为or就可以了, 暂时这个连接超时问题是解决了,但是有没有其他后遗症还不确定:(
本文由三分醉博客原创,转载请注明:https://www.sanfenzui.com/pyppeteer-bug-collection.html
文章同步更新在知乎:三分醉 - 知乎